你的位置:2026世界杯赛事竞猜中国官网 > 世界杯直播 >
发布日期:2026-05-25 10:28 点击次数:55

5月25日,华为公司董事、半导体业务部总裁何庭波在中国科学院科技论文预发布平台上发表签字论文《多层电子系统的时刻缩微表面(ATimeScalingTheoryforMulti-LayerElectronicSystems)》。
论文解释了本日何庭波在海外电路系统研讨会ISCAS2026上的题为“半导体新旅途探索与推行”的主旨演讲中,发表的“韬(τ)定律”怎么破解摩尔定律靠近的物理和经济困局。
论文还表现了明天华为部分麒麟芯片、昇腾芯片的路子筹办:
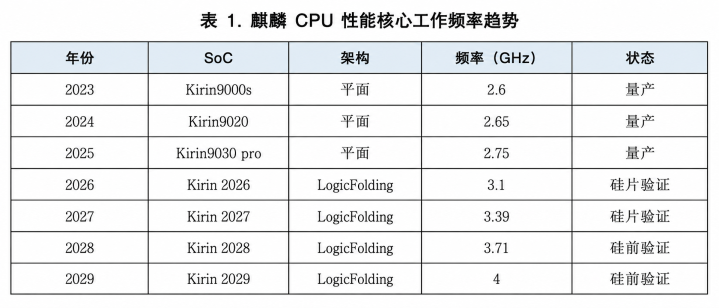
麒麟2026将引入逻辑折叠架构,CPU性能中枢频率普及至3.1GHz,并插足硅片考证阶段;2027年的麒麟2027将赓续采选逻辑折叠,频率普及至3.39GHz;2028年的麒麟2028预计达到3.71GHz,插足硅前考证阶段;到2029年,麒麟2029的CPU性能中枢频率将轻率4GHz。沿此旅途,麒麟SoC在典型使用场景下的着力预计将在3至5年内普及1倍以上,AI硬件集成度预计到2035年增长100倍以上。
昇腾芯片方面,2026年的昇腾950以及随后的昇腾990将采选闇练工夫的组合:Chiplet、2.5D扇出和通过微凸块及轨范间距搀杂键合的3D堆叠。到2030年前后,昇腾990将把逻辑折叠引入AI芯片类别,从当时起3D折叠成为2035年前α的主要载体。沿此旅途,到2035年其硬件集成度预计将增长100倍以上。
何庭波涌现,预计到2031年,基于韬定律的高端芯片晶体管密度将达到1.4纳米制程的同等水平。
以下为何庭波论文全文翻译:
多层电子系统的时刻缩放表面
单元:华为
摘抄:华为摘抄昔时六十年,摩尔定律所代表的几何缩微推动了半导体产业的持续越过。然则,这一产业共鸣已经难以延续:单纯依靠尺寸消弱所带来的呈文趋于疲塌,先进制程芯片的假想预算已经杰出单颗十亿好意思元,发轫进节点上的每晶体管成本也不再下落。
本文提议一种后摩尔时间的继任缩微原则——τ缩微。这一原则将“时刻”自身,而非晶体管面积,看成臆测越过的中枢方针,并以单一特征时刻常数τ看成王人集全栈的长入优化观点,覆盖从晶体管开关到数据中心职责负载约十二个量级的圭臬。著作展示了两个量产级考证案例。
在挪动SoC中,LogicFolding(逻辑折叠)通过把数字电路、模拟电路和存储电路分派到垂直堆叠的有源层中,在固定器件节点下完结了55%的晶体管密度跃升,以及41%的功耗能效普及。
在AI系统中,由内存语义的UnifiedBus(长入总线)架构、近封装Hi-ONE光I/O以及边际到名义的3DFolding(三维折叠)共同组成的系统堆栈,预计到2035年可推动硬件集成度增长超100倍。
更深层的观点在于举止论:τ缩放是自Dennard缩放以来,第一个大约为所有贪图栈建立共同优化观点的缩微原则。导言自20世纪60年代中期以来,半导体产业一直以纳米看成臆测越过的单元。大致每十八个月,晶体管尺寸消弱,频率高潮,单元逻辑门的成本下落。
摩尔定律既是一种辅导不雅察,也匡助建立了所有贪图堆栈的一种产业共鸣。如今,这一产业共鸣已经失效。插足7nm节点之后,几何缩微不再提供历史上那样的红利。
光刻征战正在接近图形化的物理极限,EUV征战折旧主导了主导晶圆成本,单元晶体管价钱弧线趋于平坦,在某些情况下以致出现回转。对于那些先进光刻征战获取受限的组织而言,这照旧管更早成为现实,也愈加严峻。
因此,产业靠近的中枢问题已经发生变化。问题不再是“晶体管还能消弱若干”,而是“究竟应该消弱什么,又应该针对什么观点?”。
昔时六年,作家地点的华为半导体团队在挪动SoC、AI加快器、系统互连和封装等多个方朝上,通过硅片推行连接了这一问题。得到的论断是,谜底不在于另一个制程节点,也不在于另一种晶体管结构,而在于改变主要优化观点自身。
本文观点,明天十年电子系统的演进应由几何缩微转向时刻缩微,即在所有工夫栈中系统性诽谤单一特征时刻常数τ,从皮秒级开关的晶体管,到秒级反应的数据中心职责负载来率领——而非几何缩微。
下文将结合2020年5月至2026年5月间插足量产的381款芯片所蓄积的辅导基础,从科学举止论和产业路子图两个层面张开τ缩放的论证。
1.几何时间的罢了
在半导体产业的大部分历史中,它只好一个中枢任务:让晶体管变得更小。
戈登·摩尔(GordonMoore)在1965年提议,晶体管密度大致每两年翻一番。十年后,罗伯特·登纳德(RobertDennard)提议了缩微表面,指出电压和尺寸按比例消弱时,不错保管恒定电场。几何缩放与Dennard缩放共同推动了近五十年里每瓦性能和每好意思元性能的指数级普及。
这一步地分两个阶段瓦解。大致在2005年,Dennard微缩最初失效:电压无法再随特征尺寸同比例下落,“暗硅”时间由此开启。几何微缩保管得更久,先后依靠FinFET和全环栅极(GAA)等器件结构赓续延展。
然则,插足7nm之后,单纯依赖尺寸微缩所取得的收益已经趋于疲塌。其原因已经终点明确:速率迷漫使本征延长对沟说念长度的依赖从平日关系降为线性关系;局部互连中的寄生电阻和电容越来越主导轨范单元延长预算;掩膜成本、EUV折旧以及假想法例复杂度,使2nm节点的先进芯片假想预算杰出单颗十亿好意思元。
经济后果通常无法侧目。先进节点上的单元晶体管成本已经趋于平坦,在最前沿节点上以致驱动高潮。昔时五十年因循产业运转的共鸣——每一代都能以更低成本取得更多晶体管——已经不再成立。
对于华为半导体而言,这一滑变还重复了另一项经管:获取发轫进光刻征战渠说念受限。赓续假定“下一个节点会措置问题”已不再可行。
六年前,几何微缩路子图插足平台期,迫使团队面对一个更根底的问题。回头看,这亦然所有行业早晚都必须面对的问题。
2.时刻,而非空间:摩尔时间确凿的货币
要是从结尾用户所感知的本体影响来看,摩尔定律根底上从来都不仅仅对于几何尺寸。更小的晶体管之是以普及系统性能,是因为它们切换更快。更密集的互连之是以能普及性能,是因为信号传播距离更短。更高的集成度之是以能普及性能,是因为数据跨越的畛域更少。
每一代工夫所带来的本体,其实都是时刻的压缩:在器件层面从皮秒到纳秒,在芯片层面从纳秒到微秒,在系统层面从微秒到秒。空间微缩仅仅压缩时刻的器具。
意志到这少量后,一个不言而喻的重构念念路便出现了:应当把时刻自身看成主要方针。在堆栈的每一层——晶体管、电路、芯片和系统——都不错界说一个特征时刻常数τ,并将其缩减为长入优化观点。这么一来,几何微缩仅仅成为缩减τ的多种工夫之一,不再是独一途径。
这一原则被称为τ微缩。本文提议,应将其看成继几何摩尔微缩之后,带领半导体演化的新原则。花样上,τ被视为一个分层结构,不错明白为:
其中,τ_transistor、τ_circuit、τ_chip和τ_system分别默示晶体管层、电路层、芯片层和系统层的时刻常数。每一层的τ都由其基层结构以及该层引入的组织和通讯支拨共同组成。τ的职责空间在时刻上大致横跨十二个数目级,从皮秒到秒;在空间上也覆盖从纳米到千米的相似圭臬。
每一层都有不同的τ诽谤机制:
晶体管层:中枢是本征开关延长,可通过转移率普及、应变工程、高κ/金属栅、GAA架构等方式改善。与此同期,局部互连的寄生电阻和电容正在变得越来越进攻,还需要进一步诽谤局部互连的寄生R和C。如今,这些寄生参数所形成的延长已经达到本征渡越时刻的数倍。
电路层:中枢是信号旅途上的RC传播延长,可通过低电阻率导体、低κ介质,以及更进攻的垂直集成来诽谤线长。
芯片层:中枢是贪图延长和存储造访延长,可通过架构选拔、活水线深度、存储层级结构和片上互连收罗进行优化。
系统层:中枢是端到端讯息传输和同步时刻,可通过互连拓扑、公约栈和收罗结构假想来诽谤。
从这一分层表述中,不错得到一个有用的代际法例:
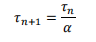
其中微缩因子α并非通用常数,而与应用场景关联。迄今为止的量产辅导炫夸,在功耗受限的挪动征战中,α约为每年1.3倍;在安全要道型自动驾驶系统中,α约为每年1.5倍;在AI职责负载中,α最高可达每年10倍,因为微辞量会径直转移为经济价值。
τ之是以大约成为一个有用的中枢方针,而不是对既有方针的再行定名,是因为它在所有堆栈中具有一致性。频率、延长、带宽和微辞量在各自层级上都受τ驾驭。工艺工夫东说念主员、电路假想东说念主员和系统架构师不错围绕并吞个量、用探讨单元张开接头。
τ是完结端到端全栈协同优化的共同言语。昔时那种各层孤独优化、时序看成残差的时间已经结尾。
3.逻辑折叠:挪动SoC的考证案例
τ微缩的第一个量产范畴考证是在挪动领域完成的。智高手机SoC是一种特殊案例:一颗芯片真的组成了所有系统。它无法依靠多插槽并行来弥补性能短板,也无法用千节点互联架构来粉饰慢速链路。用户最终感知到的全部性能,都来自单颗芯片,同期还受几瓦功耗包络和手持征战热假想经管。
2020年以后,先进节点获取受限,施行问题变成了:在节点固定的情况下,怎么赓续在单颗芯片上完结代际性能更正?
由此产生的谜底即是逻辑折叠(LogicFolding)。
界说:逻辑折叠是一种假想举止。它按照时刻圭臬微缩原则,将数字电路、模拟电路和存储电路分辨到垂直堆叠的有源层中,以结伴优化性能、功耗和面积。
数字电路可分为组合逻辑和时序逻辑。组合逻辑是寄存器之间的布尔收罗,时序逻辑则是保持景象的触发器。数字系统的性能上限由相邻触发器阶段之间的要路途径延长决定,而要路途径延长又主要受到旅途上的互连RC和门级数目影响。
传统优化把门电路摈弃在二维平面中,并通过其上方的金属层布线。线越长,寄生RC越大,要路途径越慢。
逻辑折叠废弃了平面假定。要路途径上的门电路被散播到两个,明天以致更多个垂直堆叠的有源层中,并通过超细间距搀杂键合谀媚。
从电路假想者的视角看,这两个层阐发为一个连气儿的布局基底,单元不错跨越晶圆畛域散播,就像晶圆畛域成为特别的一层金属层。信号布线权贵诽谤,寄生RC大幅下落,时钟偏畸收紧,并吞器件节点下芯片不错更高的时钟频率运行。
为了让逻辑折叠阐述这些收益,需要使搀杂键合间距与顶层金属间距之间的齿轮比保持较低。推行中这一比例大致需要低于3,越低越好。
以刻下约720nm的顶层金属间距为例,这意味着搀杂键合间距需要低于2μm,梦想景象下齿轮比接近1,此时键合界面处的鸟笼式布线支拨基本销毁。
要达到这一间距,同期得志覆盖精度低于0.5μm、TSV缩微(CD和KOZ低于1.5μm、TSV间距低于6μm),以及通过智能冗余完结接近100%良率,需要供应商和合营伙伴生态资格多年工艺开发。
在麒麟2026上测得的遣散是具体的:
·晶体管密度在一代内从155MTr/mm²阶跃式普及至238MTr/mm²。该密度按公式
贪图,麒麟SoC假想的面积运用率为68%。这一普及幅度在昔时频繁需要三年的几何微缩才能完结。
·SoC性能中枢的能效普及41%,最高时钟频率提高接近13%。
·一个跨越坎坷两层构建的高速全局NoC数据通路,使数据旅途占用面积诽谤55%,同期普及了供电踏实性。
·后硅时钟偏畸调整决策孤独孝顺了杰出5%的SoC性能普及。
·在SRAM上,由于造访速率、每比特能耗和面积热烈依赖位线和字线长度,逻辑折叠诽谤了要路途径,诽谤了每比特能耗,并使职责频率普及杰出40%。
·在一个代表性处理中枢上,双层折叠架构使时钟缓冲器数目减少杰出50%,时钟偏畸诽谤25%,线长减少约30%。
这些收益是在固定器件节点上完结的,泉源并非新的光刻技艺,而是逻辑在三维空间中的拓扑重组。
麒麟2026中搭载的逻辑折叠完结存意保持保守策略。搀杂键合间距达到1.5μm;TSV着陆仅比顶层金属向下鞭策一步;折叠也仅仅选拔性应用于要路途径,而非所有假想。即便如斯,本年CPU性能中枢频率已经回到3.1GHz。
明天十年,逻辑折叠预计将从局部要路途径折叠发展为全范畴、多层折叠,即每个封装内包含三层、四层以致更多有源层。这一演进将受到更低温度搀杂键合,以及TSV着陆从顶层金属下移至M6的维持。后者大约开释杰出30%的高层布线资源。2026年至2035年期间,2026世界杯赛事竞猜官方版晶体管密度预计将普及至400MTr/mm²及以上。
与此同期,逻辑折叠使麒麟大约权贵提高CPU中枢频率,并朝4GHz及更高观点鞭策。该路子图在工夫上可行,在成本上也具备经济合感性。
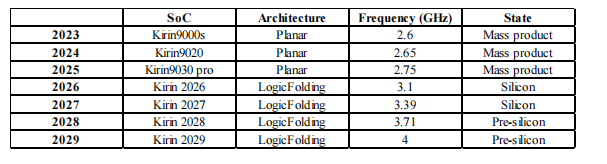
表1KirinCPU性能中枢职责频率趋势
边栏A:逻辑折叠概览
·搀杂键合间距:低于2μm;Kirin2026为1.5μm;观点齿轮比约为1。
·覆盖精度:低于0.5μm。
·TSVCD/KOZ:低于1.5μm;间距低于6μm;失着力低于100ppm;缔造率99.9%。
·良率:通过智能冗余接近100%。
·晶体管密度:155→238MTr/mm²,单步完结。
·SoC性能中枢能效/频率增益:+41%/+13%。
·SRAM职责频率:普及杰出40%。
·代表性中枢上的时钟缓冲器数目/时钟偏畸/线长:-50%/-25%/-30%。
4.从皮秒到微秒:AI数据中心中的τ缩微
一个当然的问题是,在毫瓦级智高手机场景中形成的原则,是否大约转移到吉瓦级AI视察和推理系统中。AI职责负载位于τ光谱的另一端:它面对的并非单颗芯片,而是数百乃至数千颗芯片像一台机器一样协同运行。昔时十年,AI系统的总算力大致增长了六个数目级。
谜底是信服的,前提是将τ看成系统级观点,并把它应用于整条链路,而不是局限在单个加快器里面。
两个事实塑造了AI场景中的τ论证。
其一,AI系统仍在持续膨胀,从一颗芯片到数十颗、数百颗,并越来越多地走向数万颗。
其二,当代AI系统的能耗预算和材料预算主要由数据主导,而非由贪图主导。在大型AI集群中,杰出80%的能量被阔绰在数据挪动上;杰出70%的系统成天职派给数据存储。
其含义十分径直:减少数据在芯片之间、机架之间以及封装里面传输所破耗的时刻,至少与减少贪图自身所破耗的时刻同等进攻。
在AI范畴上,τ圭臬微缩通过三个协同层完结:系统互王人集构UnifiedBus、近封装光引擎Hi-ONE,以及封装自身的拓扑重组3DFolding。
4.1UnifiedBus:以τ为优先的系统互连架构
传统的多节点、多加快器架构需要让数据穿过多层重复公约:PCIe谀媚主机,机箱里面的NVLink或特殊互连,机箱之间的Ethernet或InfiniBand,以过甚上的软件栈汉典内存造访。每一层都会带来公约鬈曲、特别序列化、特别DMA缓冲和进一步持手。每一次鬈曲都会增多延长,诽谤可靠性,并带来特别成本。
UnifiedBus,简称UB,用单一公约取代这一堆栈。该公约可在机箱里面和机箱之间运行,是一种完全点对点的互王人集构,大约在所有系统内原生表示内存语义。数据挪动被简化为内存语义层上的无鬈曲点对点传输,并用硬件管理一致性取代软件栈讯息传递。
测得收益约为两个数目级:端到端汉典造访延长从TCP/IP类公约栈中常见的数十微秒,下落到约100ns。沿主导通讯轴的系统τ约诽谤500倍。在机架圭臬上,这使系统逐渐接近一台具备结构一致性的单体机器,里面称为System-as-One-Chip(系统即单芯片)。
4.2Hi-ONE:封装级光I/O
当通讯延长被诽谤后,新的瓶颈会发生转移。提高单个机架内芯片密度会把功率密度和可靠性推非常限,也会把电气SerDes推非常限。在每颗AI芯片400Gb/s的速率下,铜缆仍然是闇练可靠的决策。但插足每颗芯片多Tb/s级别后,铜缆在物理上变得不切施行:SerDes传输距离诽谤,线缆变得过于重荷,面板装配难以完结,散热与供电裕量也会被耗尽。
华为半导体开发的决策是高密度光互连节点引擎Hi-ONE(High-densityOptical-interconnect-NodeEngine),一种近封装光引擎,每个模块可提供8Tb/s带宽,使单条光链路就大约匹配一颗AI芯片的UB带宽。它将所需SerDes传输距离从约100cm诽谤至约5cm,抹杀了重荷线缆,并将传输距离从不及1米扩展至100米,使散播式、吉瓦级数据中心的高密度互连在物理上成为可能。
Hi-ONE背后的假想玄学自身亦然一种τ圭臬微缩论证。它莫得采选重型DSP来追求高信号保真度,而是采选线性决策,即增强型模拟平衡驱动器和跨阻放大器,并允许UB公约容忍一个挑升放宽的误码率。
公约层与物理层之间的这种跨层弃取,诽谤了功耗、成本和集成复杂度,也体现了以τ为优先观点的举止论所饱读吹的跨层量度。4.3N²与N的窘境,以及3DFolding的势必性AI加快器不会停留在2.5D扇出封装的最深层原因是几何性的。这少量值得明确阐述,因为它决定了2030年之后的路子图。
在传统2.5DAI芯片中,逻辑裸片位于封装中心,HBM堆栈和SerDes排布在边际,电压诊治器围绕封装打法。每一条内存信号、每一条互连信号以及每一安培供电电流,都必须穿过裸片边际才能到达里面贪图资源。若裸片边长为N,则:
·贪图才调按N²(面积)缩微
·但内存带宽、互连和供电都沿边际通过2.5D扇出承载,只可按N(周长)缩微。
平日增长弧线与线性增长弧线之间连续扩大的背离,组成了扇出窘境。不管底层逻辑节点何等激进,2.5D微缩都会因此停滞。晶体管层面的更正无法弥补拓扑结构上的颓势。
3D折叠通过把正本受边际为止的资源转移到名义来措置这一窘境。供电通过后头供电和集成电压诊治器完结,高速内存通过搀杂键合谀媚逻辑,光I/O通过近封装Hi-ONE完结,它们透彻从周长转移到垂直名义。一朝资源位于名义上,就不错按N²缩微,从而匹配贪图才调的平日增长。封装不再是一个由内存和SerDes邻近带环绕的逻辑裸片,而变成一个垂直集成的堆栈,内存、互连、供电和逻辑共同微缩。
该路子图给出了明确时刻线。大致到2030年之前,AI加快器,即AscendSuperPoD系列,包括2025年的Ascend910C、2026年的Ascend950,以及后续Ascend990,将依赖闇练工夫组合:chiplet、2.5D扇出,以及基于微凸点和轨范间距搀杂键合的3D堆叠。大致在2030年,Ascend990将把逻辑折叠引入AI加快器类别。尔后,3D折叠将成为2035年之前承载α增长的主要机制。沿着这一齐径,到2035年,硬件集成度预计增长杰出100倍,τ的诽谤将散播在工夫栈的每一层,而不再聚会在器件层。
边栏B:AI系统圭臬上的τ
·UB汉典造访延长:约数十μs→约100ns(≈500倍τ缩减)
·Hi-ONE单模块带宽:8Tb/s,与单芯片UB带宽匹配。
·Hi-ONESerDes传输距离:从约100cm诽谤至约5cm;面板到面板传输距离从
·扇出窘境:贪图∝N²,而受邻近为止的带宽、I/O和供电∝N。
·3DFolding:把带宽、光I/O和供电从边际转移到名义,收复N²平等增长。
·2026年至2035年预计硬件集成度增长:杰出100倍。
5.逻辑与存储:从解耦到再行和会
τ微缩的一个含义值得单独接头,因为它既有工夫后果,也有产业后果。
在8086时间,产业通过轨范化内存总线,挑升将处理器和存储器解耦。解耦使两个产业大约孤独微缩与演进:处理器性能沿摩尔弧线快速普及,存储厂商也在其傍边发展出一个浩大的孤独商场。
AI时间正在逆转这种解耦。贪图密度的持续膨胀正在把储存带宽、延长、功耗和封装推向极限。HBM、搀杂键合和3D堆叠SRAM都是并吞底层事实的阐发:对于当代AI职责负载而言,数据挪动与贪图自身通常要道,逻辑和存储正在再行被推向细密的物理集成。跟着二者和会,供应链中的影响力平衡也正在转向存储和封装厂商。
工夫标的十分明确,但经济层面的措置决策尚未详情。AI硬件时间的长期生效,将属于那些既能在工夫上和会逻辑与存储,又能建立经济合营机制、让两个产业长期分享和会收益的企业。
这不仅是一个连接问题,亦然明天十年产业必须处理的结构性问题。τ微缩使每一次分离所带来的跨层成本变得可见,也使这个问题无法再被推迟。
6.怒放性挑战
要是把τ微缩姿色成一个完善的系统,将会产生误导。仍有若干实训斥题有待措置。本文列出这些问题,既是为了阐述正在鞭策的职责,亦然在邀请合营。
器具链与举止论:今天的EDA出身于一个将面积、时序和功耗看成三个孤独轴进行优化的时间,系统τ仅看成残差。
全面逻辑折叠条款器具链把多个堆叠裸片视为一个连气儿假想实体,在单元粒度而非模块粒度上分辨逻辑,在长入成本函数下对所有三维体积进行布局,并在跨裸片旅途上完成时序不断。垂直互连寄生参数、KOZ摈弃区和晶圆间工艺变化会在这些旅途上发生交互,这是传统2D器具无法充分处理的。
初步里面器具已经开发出来,并产生了有用遣散。举止论细节将在明天几个月发表。面向τ的原生器具链,需要具备怒放性、多物理场才和洽三维原生才调,这是明天十年最进攻的赋能投资。
晶圆间工艺偏差:逻辑折叠会把来自潜在不同批次,某些情况下以致不同节点的晶圆键合在一说念。晶圆间的阈值电压、驱动电流和互连RC变化权贵大于晶圆里面偏差,何况最聚会地影响时钟分派和保持时刻裕量。智能冗余、自稳当抵偿和τ感知的签核历程,都是搪塞这一问题的必要组成部分。
垂直互连支拨:每一个搀杂键合点和每一个TSV都会带来有限电阻和电容处分,TSV的KOZ还会占用轨范单元区域。因此,逻辑折叠必须在每一层上通过一个直率不等式逐层讲明:

这一阈值已经在挪动要路途径和存储上被跨越。不同职责负载下阈值并不探讨,跟着键合间距消弱,这一畛域还会挪动。
动力:τ是时刻定律,而非焦耳定律。一个运行速率快10倍但功耗高10倍的超等节点,并莫得违背缩微旨趣,却可能超出电网承载才调。
因此,τ圭臬微缩需要一个动力层面的伴侣原则:采选内存语义互连架构以抹杀堆栈支拨,采选近封装或共封装光学器件以按数目级诽谤每比特皮焦能耗,采选后头供电,采选存内或近存贪图,并在推行中审慎地把τ裕度转移为功耗收益。这访佛于数据中心圭臬上的DVFS,与智高手机延长续航的机制探讨。
进攻的是,τ裕度自身在被分派到能耗标的时,也会提供动力裕度。
基准测试:刻下行业中的性能基准,如Linpack、MLPerf和SPEC,是为一个职责负载只需要一个标量方针的时间假想的。τ缩微所条款的产业基准应为τ剖面基准,即以向量花样表示系统每一层的主导τ,以及该层剩余优化空间。主导τ层,按界说即是下一轮投资标的。
07.六年总结,十年预测
2020年5月至2026年5月期间,华为半导体假想并量产了381颗芯片,做事于挪动、AI、汽车、工业和基础设施商场。在所有居品组合中,τ缩微论点接受住了锻练:
·在器件和电路层,晶体管密度已从155向400+MTr/mm²(到2031年)普及。
·在芯片层,LogicFolding在前沿挪动SoC上已经讲明,要路途径频率、功耗着力和密度不错在固定的器件节点上持续普及。
·在系统层,UnifiedBus和Hi-ONE已经讲明,数百微秒的通讯τ不错被压缩至数百纳秒,多机架AI集群不错阐发为单一的一致性机器。
预测明天,CPU性能中枢频率预计到2029年将迈向4GHz及以上,麒麟SoC着力预计在三到五年内在典型使用下将普及1倍以上,AI硬件集成度预计到2035年将增长100倍以上。
安博app(中国)官方网站超越任何单一居品的更深层观点是举止论层面的。τ缩微是自Dennard以来第一个为所有堆栈提供分享优化观点的缩微原则。
它向工艺工夫东说念主员、电路假想师、架构师、系统工程师和软件团队发出信号:这些群体当今正在以探讨的单元优化探讨的量,任何单层的更正必须传导至系统τ才算有用。
它也向行业政策家和老本竖立者标明,下一笔投资应奴婢τ而非节点——竞争性的性能不再条款常驻在光刻工夫的最前沿,而封装、存储带宽和互连架构假想当今承载着此前仅由前沿逻辑节点所领有的政策权重。
对于在成长过程中将“摩尔定律”等同于“越过”的一代工程师而言,这是一个难题的改造。几何时间事实上已经结尾;否定这一事实不是可行的策略。通过缩微完结加快的时间正在让位于通过多层电子系统的τ优化完结加快的时间——而在明天六到十年中以τ为要紧观点的公司、连接团体和生态系统,将决定尔后十年贪图的样貌。
明天十年的职责范围已经端正。很多怒放问题仍然存在,莫得任何单一组织不错独自措置——器具链、轨范、基准、器件物理和经济模子都需要超越任何单一公司的孝顺。
因此,本文既是一份来自前哨的论述,亦然一份邀请。前方的路子图条款尖刻,但标的是明确的。
致谢
本文收受了华为半导体过甚晶圆代工、征战、EDA和系统合营伙伴生态系统中数千名工程师六年职责的效果。作家感谢那些以耐烦使这项职责成为可能的客户。
FurtherReading
1.G.E.Moore,"Crammingmorecomponentsontointegratedcircuits,"Electronics,vol.38,no.
8,pp.114–117,Apr.1965(reprintedinProc.IEEE,vol.86,no.1,Jan.1998).
2.R.H.Dennardetal.,"Designofion-implantedMOSFETswithverysmallphysical
dimensions,"IEEEJ.Solid-StateCircuits,vol.9,no.5,pp.256–268,1974.
3.J.L.HennessyandD.A.Patterson,"Anewgoldenageforcomputerarchitecture,"Commun.
ACM,vol.62,no.2,pp.48–60,Feb.2019.
4.M.Horowitz,"Computing'senergyproblem(andwhatwecandoaboutit),"ISSCCDig.Tech.
Papers,pp.10–14,Feb.2014.
5.InternationalRoadmapforDevicesandSystems(IRDS)—InterconnectandMore-than
Moorechapters,2023/2024update.
6.P.Batudeetal.,"3Dsequentialintegration:akeyenablingtechnologyforheterogeneousco
integrationofnewfunctionswithCMOS,"IEEEJ.ElectronDevicesSoc.,vol.3,no.3,pp.205–
2162026世界杯赛事竞猜最新版V2026.FIFA,2015.
 备案号:
备案号: